Branching, Release, Deployment: Why All Three Must Align
Deploy without releasing, release without deploying. Three tracks shaped by one set of real constraints — and what misalignment between them really costs.
Branching, Release, Deployment: Why All Three Must Align
A feature ships three weeks after the code merges. A rollback takes four hours because nobody can name which of the seventeen changes broke production. A "simple deploy" turns into a five-person meeting on a Thursday. These aren't unrelated problems. They're symptoms of treating "ship it" as one decision when it's actually three: how code converges (branching), how it reaches an environment (deployment), and how users see it (release).
Every team has a branching strategy. Every team has a release strategy. Every team has a deployment strategy. Most engineering posts pick a side inside one of them — Gitflow vs trunk-based, blue-green vs canary, SemVer vs rolling. The side you picked matters less than where it came from.
Underneath every stack sits a small set of constraints, some real (customer upgrade models, regulatory windows), some manufactured (calendars adopted by habit, capability gaps nobody fixed), and those constraints are the core problem. Misalignment between the three strategies doesn't create them. It amplifies their cost and masks where they live. Coherence across the three beats modernity in any one of them, because coherent strategies are the ones derived from constraints that are real.
TL;DR
- Branching, release, and deployment are three independent tracks — and underneath them sits the core problem: your constraints, some real (customer upgrade models, regulatory windows), some manufactured (copied calendars, capability gaps nobody fixed)
- Misalignment between the tracks doesn't create those problems — it masks them (Gitflow hiding a slow CI pipeline) and amplifies them (a monthly window coupled to deployment turning one real constraint into three weeks of idle code)
- Deployment puts code in an environment. Release exposes it to users. The two can and should be decoupled — deploy without releasing (dark launch behind a flag), release without deploying (flip a flag on code already in production)
- Coherence across the three beats modernity in any one of them — derive each strategy from a named real constraint, strip the copied ones, then fix the capability gap that remains
Why People Confuse These Three Things
For most of software history, all three happened in the same event. You cut a release branch, packaged a versioned build, and shipped it to a customer's server overnight. Branch, release, and deployment were synonyms because they had to be. One ceremony, one calendar entry, one rollback plan.
Continuous delivery broke that. Once deployment automation made it easy to push code many times a day, the three timelines decoupled. Branching became a near-continuous flow. Deployments became routine. Releases became a separate product decision about visibility and exposure. But many teams still use the same word for all three, and the cadences quietly drift apart.
The misalignments that result rarely point at one specific strategy. They're coherence problems where the three don't agree on cadence, scope, or who decides what ships. The right strategies for an embedded firmware image look nothing like the right strategies for a SaaS web app. The question isn't whether each individual strategy matches current best practice; it's whether your three fit together and match what you actually ship and to whom.
The right mental model is three independent tracks. Branching controls integration cadence. Release controls user exposure. Deployment controls environment risk. The slowest track sets the cadence the team actually feels. Fast integration feeding a slow deploy pipeline piles up merged code nobody is testing in real conditions. A rolling release forced onto an application that can't absorb it breaks the application — online multiplayer games need every player on a synchronized version, or matchmaking fails. Speeding up one track without addressing the slower ones moves the bottleneck. It doesn't remove it.
And the strategy layer doesn't just move work around — it filters the signals. A loose branching model absorbs a slow CI pipeline into quarterly integration pain nobody attributes correctly; a coupled deploy-and-release calendar turns one team's real marketing window into everyone's idle month. The constraint is the disease. The strategies decide whether you feel the symptoms.
A note on AI in this post. DORA's 2025 research describes generative AI as an amplifier rather than a new mechanic. Adoption correlates with both higher delivery throughput and higher delivery instability. The branching, release, and deployment models themselves don't change; what changes is the rate at which a misalignment between them turns into failure. AI's effect on DevOps practice deserves its own treatment, and this post is not it. This one stays on the three tracks and how they fit together.
What Is a Branching Strategy?
Throughout this section, "main" refers to your repository's trunk branch — the primary integration line, regardless of its actual name.
A branching strategy is the system your team uses to introduce, track, and collaborate on code changes. It defines how individual developer changes influence the shared codebase, how those changes are integrated into the repository, and what history the team can read after the fact. The four mainstream options are trunk-based development (TBD), GitHub Flow, GitLab Flow, and Gitflow. Each makes different trade-offs about workflow shape, collaboration model, and integration cadence. The mechanics of each are the topic of the linked deep-dive.
The branching choice cascades into the release and deployment strategies the team can run. Short-lived branch models almost certainly need feature flags to manage incomplete features in main. Long-lived branch models need a defined integration ceremony and a way to handle hotfixes against multiple supported release lines. The strategy isn't just about Git; it sets the boundaries of what release and deployment models are even available downstream.
Related: Full deep-dive on Git branching strategies — trunk-based, GitHub Flow, GitLab Flow, and Gitflow, with the trade-offs each model makes — coming soon. Link will appear here.
What Is a Release Strategy?
A release strategy is how, when, and to whom you expose new functionality. "Release" is a product decision dressed up in engineering language. It covers versioning (the promise the number carries), packaging (what rolls back atomically), and consumption (all at once or progressively).
The release strategy you can run is bounded by your packaging model. A SaaS product on a rolling release treats every merge as a potential release, gated by flags and rollout percentages. A versioned product under SemVer (a CLI, a Kubernetes operator, an embedded firmware image) ships discrete artifacts with changelogs and LTS windows. Microsoft's Engineering Playbook makes the distinction cleanly: continuous delivery means the artifact is always shippable, not that every artifact ships.
The most under-discussed part of release strategy is consumption coupling. If your customers pin to specific versions, your release cadence is constrained by their upgrade tolerance, not your engineering velocity. No amount of internal decoupling changes that ceiling.
Related: Detailed guide on release strategy patterns and versioning trade-offs coming soon. Link will appear here.
What Is a Deployment Strategy?
A deployment strategy is the technical mechanism that gets new code running in an environment (every environment, not just production). It breaks down into three independent choices. Progression is which environments code passes through and the gates at each hop. Delivery mechanism is push pipelines vs pull-based GitOps, immutable artifacts vs in-place updates. Cutover is how new code replaces old once it arrives: blue-green, canary, rolling update, recreate, with adjacent variants like shadow, ring, and A/B (see HashiCorp's Zero-Downtime Deployments guide).
What you can actually run on each axis depends on your infrastructure and your release model. Blue-green needs capacity headroom; canary needs traffic routing and observability; both need a rollback path you've actually rehearsed. The cutover choice is mostly an availability and rollback question, not a feature-exposure question. That's what the release strategy handles.
Related: Full deep-dive on deployment strategies — progression, delivery mechanism, and cutover patterns (blue-green, canary, rolling), with the trade-offs each makes — coming soon. Link will appear here.
Deployment Without Release. Release Without Deployment.
This is where most teams' mental model breaks. A deployment puts new code into a running environment. A release exposes that code to users. The two events can happen on separate timelines.
Deployment without release. Code merges to main on Tuesday, deploys to production behind a feature flag set to off. Zero users see it. The code is live in production, exercising the database, sitting in the same memory space as everything else, fully observable. Engineering has shipped. Product hasn't released. When marketing runs the launch on Friday, the flag flips and the feature appears. The deployment happened three days earlier and got soaked under real load. The release is a configuration change, not a code change.
Release without deployment. A feature has been in production for two weeks, gated to 1% of traffic for monitoring. The team raises the flag to 100%. No code shipped. No pipeline ran. Users get a new experience anyway. The release happened without a deployment.
Once you internalize this, the second-order benefits stack up. Rollback becomes a flag flip instead of a deploy. Risk-bearing experiments become routine rather than special. The deployment pipeline can run at the engineering team's natural cadence, not the marketing calendar's. The release process can serve customer-facing requirements without holding code hostage. Is your team treating these as one decision or two? The answer determines how much friction your DevOps practice quietly accumulates each week.
How Does Misalignment Show Up?
Misalignment is rarely loud: it's the slow tax on every release cycle that nobody assigns a name to. It's also rarely the root cause. Underneath each example below sits a constraint: a slow pipeline, a missing flag platform, a release calendar nobody re-examined. The misalignment is what that constraint looks like after the strategy layer has finished masking or amplifying it. Each of these is the team's own to fix; the genuinely external constraints come in the next section. Each example separates the real constraint from the self-imposed copy. The fix is never "abandon the constraint" — it's "stop letting it cascade into tracks that didn't inherit it," then fix the constraint that's actually left.
Gitflow that hides a slow CI pipeline
A single-version SaaS team runs Gitflow (develop, release branches, dual-merge hotfixes), a model built to manage multiple shipped versions, on a product that ships one. The ceremony taxes all three tracks.
Release: features can only reach users through a release-branch cut, so release cadence is welded to branch ceremony.
Deployment: five branch types onto three environments makes the mapping ambiguous: develop to staging, release to UAT, main to prod? Every environment runs a different branch, so no environment tested exactly what ships, and each deploy starts with a "which branch goes where?" conversation.
CI: develop is nominally the trunk, but features land on it weeks apart. So CI runs often while integrating rarely. Each green feature-branch build tests one change against a stale base, and changes first meet each other in a late merge or on the release branch. That hides the pipeline in both directions. If CI/CD is fast, the branching is the constraint — the speed is wasted on isolated branches. If CI/CD is slow, you hardly notice. Forty-five minutes barely matters when merges are rare, so it never gets fixed. Push fifteen merges a day through it, trunk-based style, and it would be unbearable within a week.
Even Gitflow's author steers continuously delivered web apps toward simpler models. The model isn't just slow — it's an anesthetic. I've watched a forty-five-minute pipeline survive years of complaints precisely because the Gitflow cadence kept anyone from feeling it — until the team tried to merge ten times a day and it became the whole problem inside a fortnight.
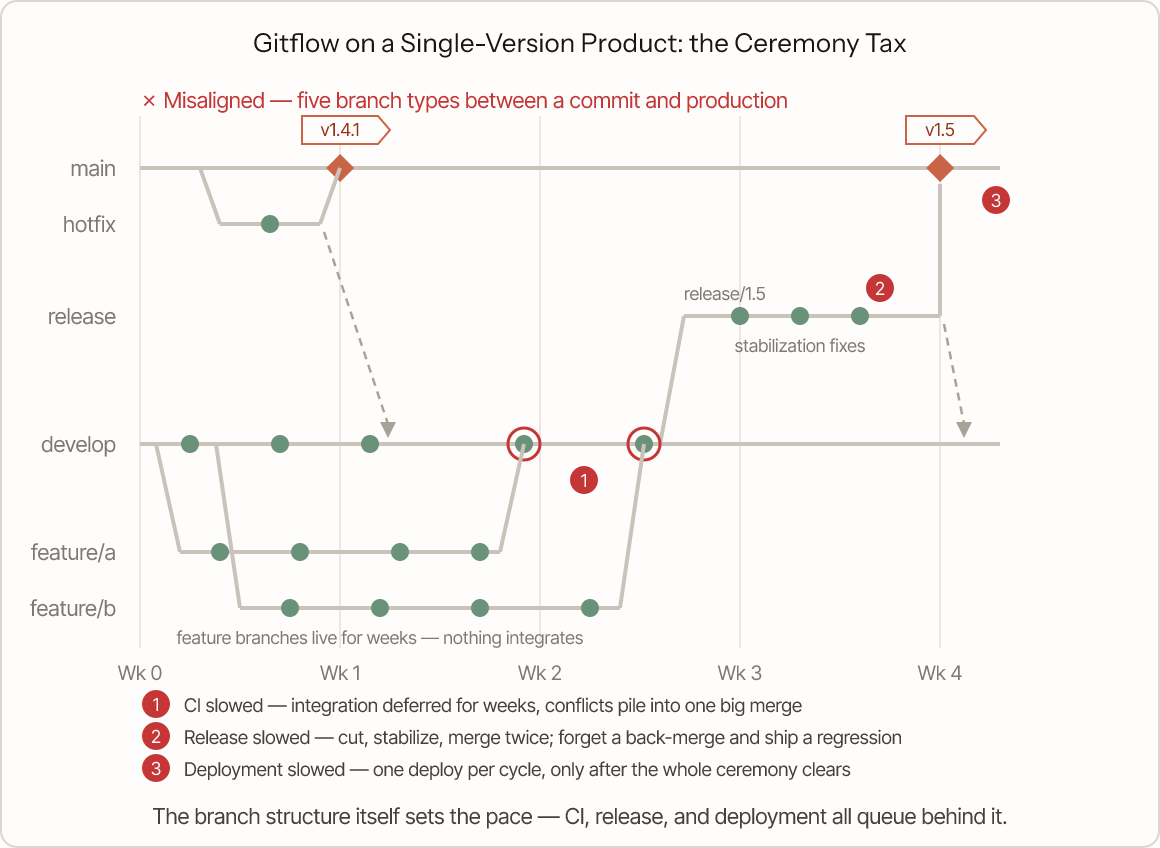
Every branch type in the ceremony is doing a job Gitflow assumes you need — multi-version support, scheduled stabilization. On a single-version product none of those jobs exist, but the tax still gets paid: integration waits on feature branches, production waits on the release branch, and the slow CI underneath it all never hurts enough to get fixed.
Trunk-based branching with a calendar-driven monthly release
Where Gitflow masks its underlying constraint, this shape amplifies one. The branches are short, the merges are clean, and then the code sits in main for three weeks waiting for the release calendar. The buried mistake is the assumption that deployment has to match the release cadence: because users can't see the feature until the window opens, the code doesn't ship anywhere at all.
But the window is a release constraint: it says when users see the change, not when code is allowed to reach production. Held to the same calendar, deployment goes dark for weeks. Engineers stop feeling the connection between merging and shipping, and the feedback loop you optimized for at the Git layer is severed by a coupling the release calendar never actually demanded.

The branching layer is fast — short branches, clean merges — but the release calendar has been copied onto deployment, so three weeks of merged work sits on main: not in production, not released, generating no feedback.
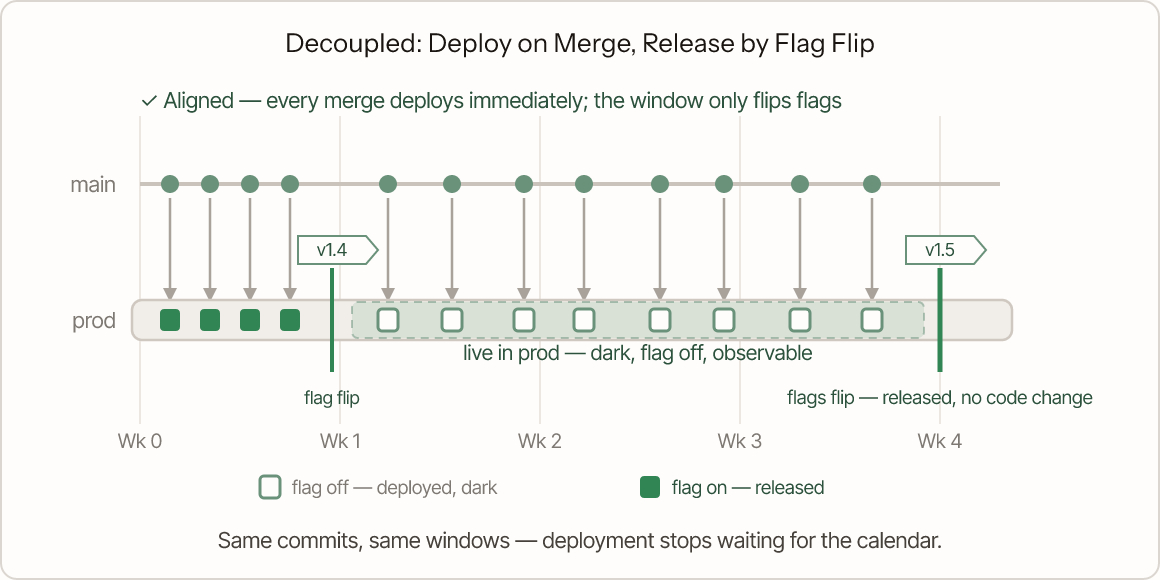
Same commits, same monthly windows. Every merge deploys to production immediately with its flag off — dark, invisible to users, but soaking under real load. The window stops being a deploy event: when it opens, the flags flip and the features are released without a code change.
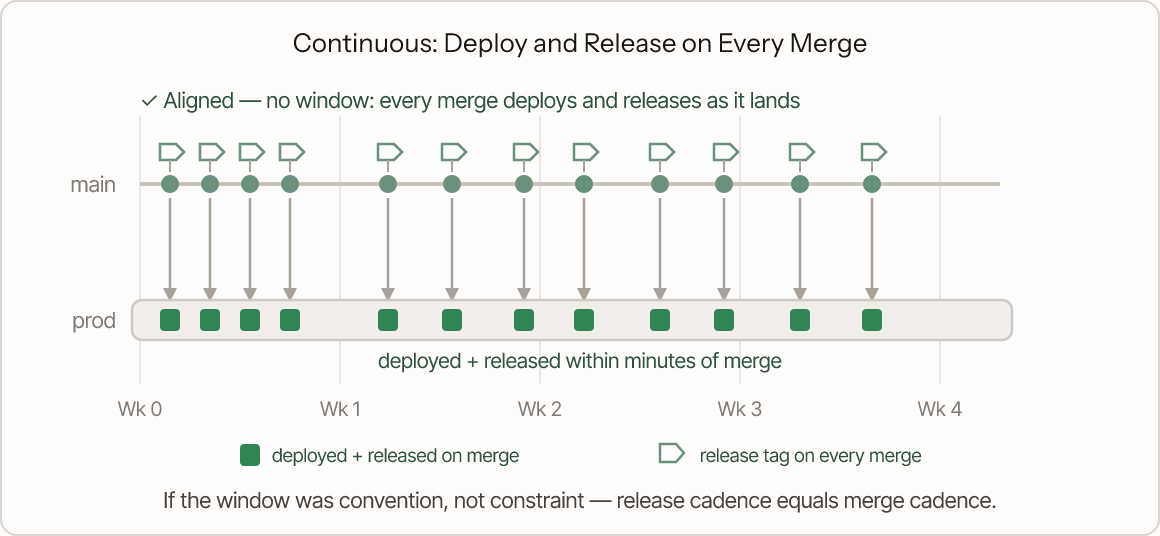
And if the monthly window turns out to be convention rather than a real constraint, the third option is to drop it: every merge deploys and releases as it lands. Flags still gate incomplete work inside each merge — which is exactly what the continuous-deployment failure below is missing.
"But deployments cause errors and downtime too"
It's the strongest objection to everything above, and the one I hear most when I suggest deploying more often. The fear is rational: for a team that deploys monthly, every deployment it has ever run genuinely was dangerous, because each one carried a month of changes. But that risk is a property of batch size, not of deployment as an activity. The calendar doesn't reduce it — it concentrates it into one compound event where any failure has forty possible causes (the four-hour rollback from the top of this post). A decade of DORA research finds throughput and stability are not a trade-off: frequent deployers have lower change failure rates and recover faster (DORA's software delivery metrics). The mechanism, the fear loop that keeps reluctant teams stuck, and the on-ramp that never requires more user-facing risk than a team takes today are covered in the deployment strategies deep-dive (coming soon).
Continuous deployment with no feature flag platform
Every merge ships to all users immediately. Half-finished features can't merge, so they fester in long-lived branches, and the team quietly slides back toward Gitflow. The branching and deployment strategies look modern; the release model forces the branching strategy backward.
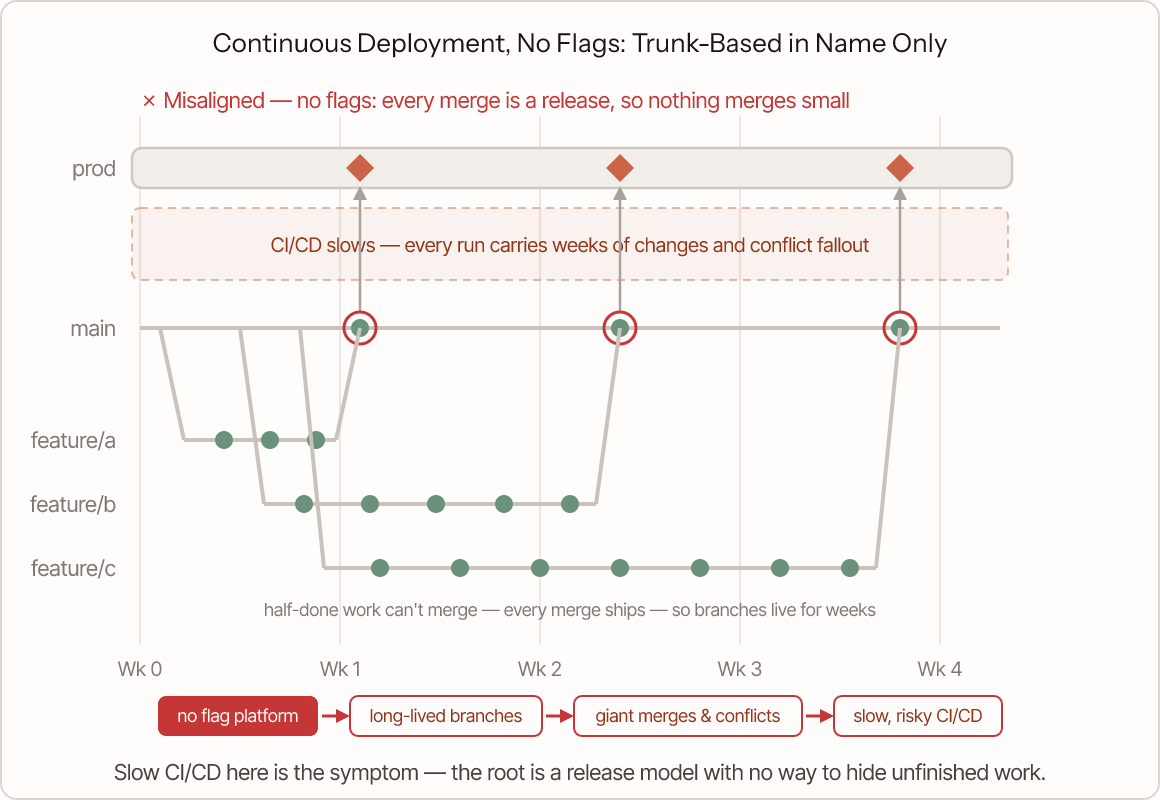
Read the chain from the root: with no flag to separate exposure from deployment, completeness becomes a merge precondition, branches run long, and the merges that finally land are giant. The slow, risky CI/CD is the symptom at the end of that chain, not the cause — each run carries weeks of changes and the conflict fallout that comes with them. Add a flag platform and the chain unwinds from the front.
The realignment is a flag platform: incomplete work merges and deploys dark, and exposing a feature becomes a per-feature release decision instead of a side effect of deploying.
What Happens When the Constraint Is Real?
The misalignments so far were couplings to strip out: remove the copy and the constraint underneath sits quietly. The constraints here are heavier. They come from outside the engineering organisation (a regulator's release window, a contract promising customers fixes on the version they pinned), and the organisation has to adhere to them whether it likes them or not. They can't be designed away. They can only be mishandled: by letting them cascade into tracks they never bound, or by paying their cost without the policy that keeps the bill finite. The first example below caps how often you ship but not how fast you can work; most of the stack it seems to bind, it doesn't. The second genuinely dictates structure, and stays affordable only with an explicit cap.
A fixed release window caps frequency, not speed
A genuinely fixed release window (a regulator's quarterly approval, a customer's change calendar) caps how often you ship, not how fast you work behind it. Integrate continuously and deploy to dev, staging, and UAT continuously, and you validate far more features per window; only the release waits.
The fear that this means a bigger, riskier release is half misattribution and half real. The merge crunch comes from holding features on branches, not from speed; integrate continuously and the release just tags what's already on main. What's real is blast radius: more lands on users at once, a job for feature flags or a ring rollout, not a reason to slow down. The one thing that genuinely caps batch size is the customer's capacity to absorb change. And if that's why the window exists, that's the real constraint, where the next example begins.
A release branch per supported version: what the legitimate constraint costs
When customers pin to a version and expect fixes without a forced upgrade, every release becomes a long-lived branch (release/1.4, release/1.5) so a hotfix can be cut against exactly what each customer runs. This is the coherent stack for versioned products, and current guidance is consistent on the mechanics. Branch as late as possible. Never develop on the release branch. Fix bugs on main first, then cherry-pick them to each affected line: the "upstream first" policy (trunk-based development's branch-for-release, GitLab's branching strategies). Tag a new patch version on the branch for every backported fix.
The cost scales with every line you keep alive: each supported branch is a hotfix target, a backport queue, and a full regression matrix of its own. That's why mature versioned products cap the window explicitly rather than letting support accrete. Kubernetes maintains release branches for only the latest three minor versions, roughly fourteen months each. Commercial products publish the same idea as N−2 or LTS policies.
The branch structure is the legitimate answer to a consumption constraint; the published support window is what keeps that answer affordable. A team running this stack without an end-of-support policy hasn't aligned with their constraint — they've signed up for unbounded maintenance.
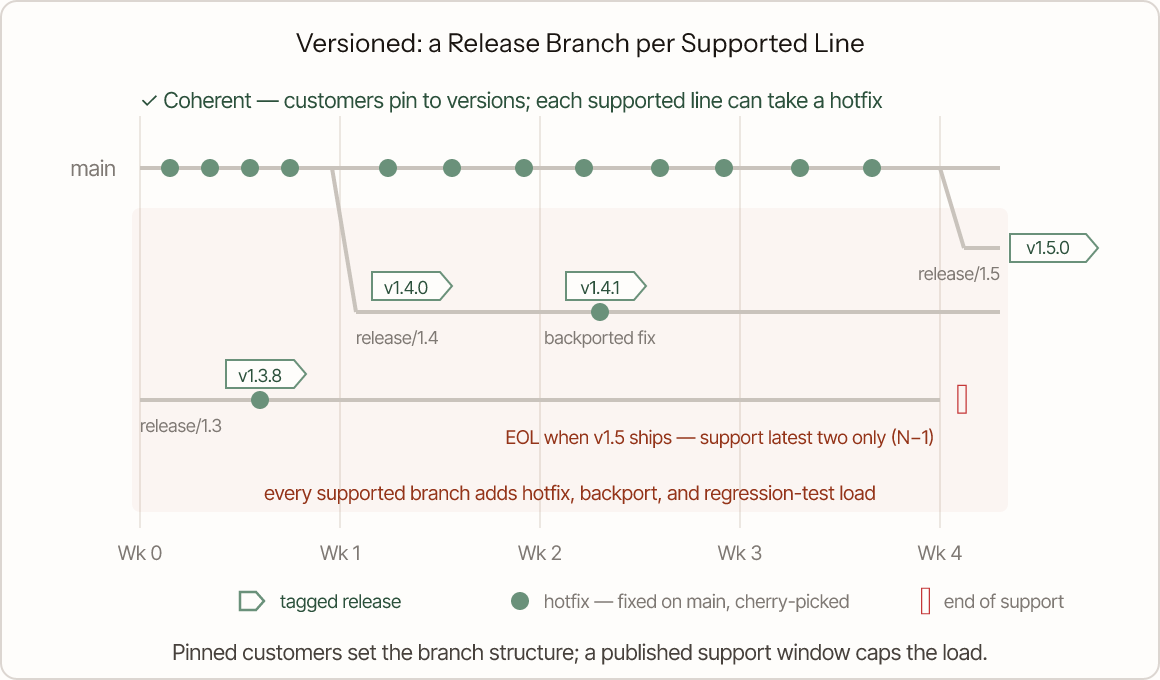
Branch late, tag each release, fix on main and cherry-pick to each line. The amber zone is the point: every live branch is its own backport queue and regression matrix — affordable only with an explicit support cap.
The deployment strategy follows from the same constraint: the customer owns the production deploy, so progressive delivery moves before release instead of after. That's the alignment test passing in reverse: one real constraint cascading coherently into all three tracks. The misalignment is the team that copies SaaS assumptions (deploy-on-merge, release-by-flag) onto production it doesn't control. The mechanics (build-once promotion, pull-based channels, rollback-engineered artifacts) are in the deployment strategies deep-dive (coming soon).
Whether the constraint is self-inflicted or external, the recovery is one move: name it, then check whether your strategies mask it, amplify it, copy it where it doesn't belong, or pay its cost without a cap. The next section turns that into diagnostic questions.
How Do You Test Alignment on Your Team?
The right question isn't "which branching strategy is best." It's "which constraints are real, and which did we manufacture?" Real constraints (customer upgrade model, regulatory windows, architecture, contractual SLAs) are inputs you can't choose. The Theory of Constraints lesson for DevOps is that the slowest track sets the cadence the whole team feels, so optimizing any other track past the bottleneck just stockpiles work-in-progress nobody can ship. The expensive misalignments aren't the bottlenecks reality imposes. They're the cadences your team copied onto strategies that didn't need them — and the real bottlenecks your strategies have stopped you from feeling.
Every pattern above reduces to the same shape: a constraint underneath, a misalignment on top, and one move that realigns the three tracks. The table recaps them.
Work through the questions below at your next architecture review. The constraint questions surface what's actually fixed. The alignment questions test whether the three strategies fit together.
Constraint questions: what's actually fixed?
For each strategy, separate genuine external constraints from cadences adopted by convention.
Branching:
- What's forcing your current integration cadence: tooling, audit trail, regulatory requirement, or convention?
- Does your domain genuinely require multiple long-lived release lines, or only a support history for hotfixes?
- Is your branching model solving a problem you actually have (multiple shipped versions, regulated audit lines), or one inherited from a product that did?
- How long can a feature legitimately stay on a branch before the cost of merge debt outweighs the benefit of isolation?
Release:
- Who decides when users see a new feature: engineering, product, marketing, or the customer?
- Are your customers pinned to versions they upgrade on their own schedule, or do they take whatever you ship?
- Is your release cadence imposed by an external model (regulated firmware, on-prem installer, contractual SLA) or by internal calendar?
- If your release window is genuinely fixed, is it capping how often you ship — or have you let it cap how fast you work behind it? And if batch size is the limit, is that your pipeline or your customers' capacity to absorb change?
- What's the smallest release unit your packaging model allows: one change, a tagged version, a quarterly bundle?
Deployment:
- What's the technical floor on how often you can push to a production-like environment? (Pipeline duration, infrastructure provisioning, manual approvals.)
- Are the same gates required in non-prod environments, or only in prod?
- Where are the manual steps, and are they manual because of audit, risk, or because nobody automated them?
- How long does a rollback take, and does that time match your team's actual recovery appetite?
Alignment questions: do the three agree?
Once you've isolated what's actually fixed, test whether the three strategies fit together.
- How often do you deploy to production? How often do you release a new feature to users? If those numbers are identical, you've coupled the two — confirm that's a choice, not a default.
- Which of the three strategies is currently the slowest? Is that slowness justified by an external constraint you just identified, or did the team adopt it by convention?
- Is any other strategy running faster than the slowest can absorb? (Fast merges piling onto a slow deploy; fast deploys with no flags to gate exposure.)
- What might your current setup be hiding? A branching model that integrates rarely can absorb a slow, flaky pipeline for months — if you had a capability gap, would your workflow force you to feel it, or quietly route around it?
- For each pair (branching↔release, release↔deployment, branching↔deployment), is one constraining the other? Does that constraint serve the business, or just reflect inheritance from an unrelated layer?
- If you replaced one strategy with a popular alternative (trunk-based development, continuous deployment, canary), would the other two operate at the new cadence without breaking?
The Takeaway
A team running Gitflow + scheduled releases + blue-green deployments because they ship versioned software to regulated customers is doing better engineering than a team running TBD + monthly releases because someone read a DORA report and only changed one track. Coherence matters more than modernity.
The constraint questions usually surface one strategy that's genuinely fixed: most often release, sometimes deployment, rarely branching. Everything else is a cadence the team chose. The mistake is letting the real constraint cascade into strategies that didn't inherit it: long-lived branches because the release is quarterly, manual prod deploys copied into manual non-prod deploys, blue-green infrastructure paired with a monthly release calendar. Strip the self-imposed copies out, and the bottleneck that remains is the one worth investing in.
That remaining bottleneck is usually a capability, not a strategy: a slow pipeline, a missing flag platform, an unrehearsed rollback. Alignment doesn't substitute for fixing it; alignment is what makes it visible and tells you it's the one that matters. The leverage I keep coming back to isn't the strategy on the whiteboard — it's the shared capability underneath it. Fix the pipeline, the flag platform, or the rollback once, and every team downstream gets faster at the same time. That's the line between a strategy debate and a scaling investment. Notice, too, that branching is almost never the strategy you change to fix a misalignment. But it's often where one is created (a model copied from products with constraints you don't have) or hidden (integration tolerances loose enough to absorb the signal).
The other mistake is upgrading one strategy in isolation. New pipeline, same branching model. Trunk-based merges, same hand-cranked release.
FAQ
What's the difference between a release and a deployment?
A deployment is the technical act of putting new code in a running environment. A release is the moment users get access to that code or feature. Feature flags are the most common mechanism: code can be deployed for weeks before the flag is flipped to release the feature.
Can you do canary deployments without feature flags?
Yes, at the infrastructure layer. A canary deployment routes a small percentage of traffic to a new version regardless of feature flags. But canaries and feature flags solve different problems: canaries de-risk the deployment itself (is the new build healthy?), while flags de-risk the release (should users see this feature?). Most mature teams use both layered together.
Isn't deploying to production more often riskier?
No — a decade of DORA research finds the opposite: teams that deploy more frequently have lower change failure rates and recover faster (DORA's delivery metrics). Deployment risk scales with batch size, not deployment count. A monthly deploy concentrates every change from the month into one compound event with dozens of possible causes per failure; small frequent deploys shrink the blast radius, make diagnosis near-trivial, and keep the deployment machinery rehearsed. Deploying dark behind a feature flag removes user exposure from the deploy event entirely.
Does trunk-based development require continuous deployment?
Not strictly, but the combination is the natural fit. TBD assumes branches measured in hours and at least one daily merge (DORA, Trunk-Based Development capability). If main is the integration point but deployments happen monthly, you've recreated a code-freeze problem by another name. Most teams that adopt TBD seriously also move toward deploy-on-merge with feature flags managing user exposure.
What is progressive delivery?
Progressive delivery is the operational discipline of releasing changes to small user segments and expanding based on observed behavior, typically combining canary deployment with feature flags. The term was coined by James Governor of RedMonk in 2018 and is now used widely across the feature-management ecosystem (Flagsmith, LaunchDarkly). It's release strategy and deployment strategy working in concert: deploy progressively to environments, release progressively to user cohorts.
How do versioned products (CLIs, SDKs, embedded software) fit this model?
Versioned products keep deployment, release, and branching closer together by necessity, because the artifact itself is the unit of distribution. Gitflow, semantic versioning, and customer-driven deployment form a coherent stack here. The deploy/release decoupling that SaaS teams get from feature flags shows up in versioned products as version pinning and gradual customer upgrade cycles instead.
Sources
- DORA. "Balancing the tensions of AI." dora.dev/insights/balancing-ai-tensions/. Accessed 13 June 2026.
- DORA. "DORA's software delivery metrics." dora.dev/guides/dora-metrics/. Accessed 13 June 2026.
- DORA. "Trunk-based development (capability)." dora.dev/capabilities/trunk-based-development/. Accessed 13 June 2026.
- Microsoft. "Continuous Delivery: Engineering Playbook." microsoft.github.io/code-with-engineering-playbook/. Accessed 13 June 2026.
- HashiCorp. "Zero-Downtime Deployments: Well-Architected Framework." developer.hashicorp.com. Accessed 13 June 2026.
- Vincent Driessen. "A successful Git branching model." nvie.com. Accessed 13 June 2026, originally published 2010.
- Trunk-Based Development. "Branch for Release." trunkbaseddevelopment.com/branch-for-release/. Accessed 13 June 2026.
- GitLab. "Branching strategies." docs.gitlab.com. Accessed 13 June 2026.
- Kubernetes. "Releases." kubernetes.io/releases/. Accessed 13 June 2026.
- James Governor (RedMonk). "Towards Progressive Delivery." redmonk.com. Accessed 13 June 2026, originally published 2018.
- Flagsmith. "Progressive Delivery." flagsmith.com/blog/progressive-delivery. Accessed 13 June 2026.